
솔솔
[ELK] MySQL의 데이터를 ELK 스택으로 가져와서 시각화하기 본문
반응형
설치환경
MacBook Pro 14
Apple M1 Pro
설치목록
UTM (Virtual machines for Mac)
Ubuntu 22.04.4 LTS
Elasticsearch
Logstash
Kibana
MySQL Database
mysql-connect-java-8.0.18.jar
🍀 MySQL JDBC 드라이버 다운로드 받기
Logstash는 Java로 만들어진 애플리케이션으로 MySQL 데이터베이스와 통신하기 위해 JDBC(Java Database Connectivity) 드라이버를 필요로 하기 때문에 다운로드 받음.
1. JDBC 다운로드
# JDBC 다운로드
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-8.0.18.zip
# zip 형식의 압축 파일을 해제 패키지 다운로드
sudo apt install unzip
# JDBC 압축 파일 헤제
unzip mysql-connector-java-8.0.18.zip
2. JDBC를 Logstash의 jar폴더로 이동
sudo cp mysql-connector-java-8.0.18/mysql-connector-java-8.0.18.jar /usr/share/logstash/logstash-core/lib/jars/
🍀 MySQL에 데이터 넣기
작업 할 데이터 파일을 연결할 MySQL에 데이터를 Import시켜 놓기
(저는 캐글의 타이타닉 데이터 .csv파일을 받아서 Import 했습니다.)
🍀 Logstash 설정 파일 작성 및 프로그램 재가동
1. "/etc/logstash/conf.d/"폴더 아래에 .conf 파일 작성하기
input {
jdbc {
# JDBC jar파일 위치
jdbc_driver_library => "/usr/share/logstash/logstash-core/lib/jars/mysql-connector-java-8.0.18.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/your_database"
jdbc_user => "your_username"
jdbc_password => "your_password"
statement => "select * from {테이블 명}"
}
}
output {
# 콘솔창에 어떤 데이터들로 필터링 되었는지 확인
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["http://localhost:9200"]
# Elasticsearch 에서 "titanic" 라는 이름으로 인덱싱
index => "titanic"
}
}
2. elasticsearch & logstash 재가동
# 재가동
sudo systemctl restart elasticsearch
sudo systemctl restart logstash
# 가동 확인
sudo systemctl status elasticsearch
sudo systemctl status logstash
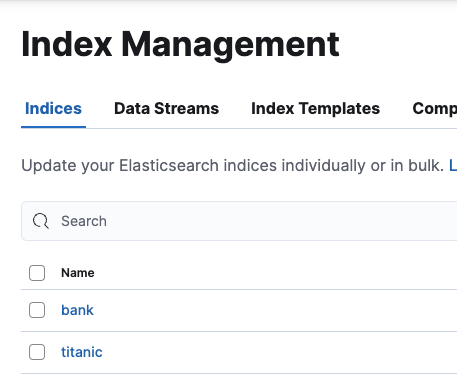
3. elasticsearch-head에 인덱스 생성 확인

4. Kibana에 접속해서 인덱스 생성 확인
🍀 Kibana로 시각화 하기
1. Kibana 켜기
# 키바나 연결
sudo systemctl start kibana
# 키바나 연결 상태 확인
sudo systemctl status kibana
2. Kibana의 Visualize Library에서 MySQL 연결해서 생성한 인덱스로 시각화 하기
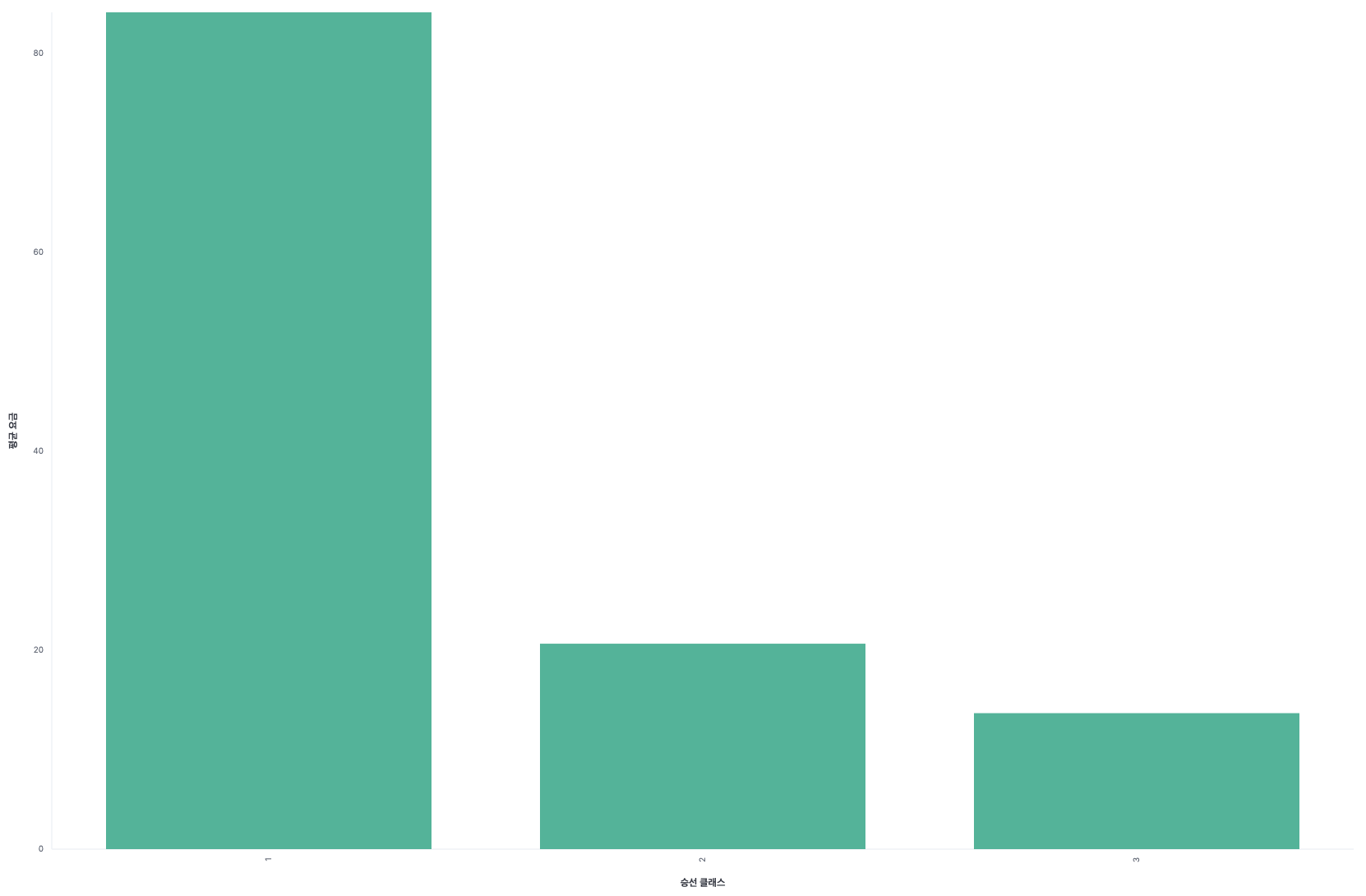
💭 마이 띵킹 💭
예전에 데이터를 시각화를 해본 경험이 있는데 이 때는 정말 많은 작업이 필요했다. 원하는 데이터를 쿼리로 작성하고 JSON 형식으로 프론트엔드로 보내 차트 라이브러리를 사용해 차트를 생성하는 과정이 생각보다 복잡했다. 데이터가 많아질수록 쿼리 작성도 힘들었고 그 데이터를 가공해 시각화하는 데 많은 시간이 걸렸다.
하지만 ELK 스택을 알게 된 후 데이터 시각화 작업이 얼마나 편리해질 수 있는지 깨달았다. ELK 스택을 구축하면 쿼리 작성 없이도 Kibana를 통해 원하는 데이터를 시각화할 수 있다. Kibana의 UI는 직관적이어서 몇 번의 클릭만으로도 복잡한 차트를 쉽게 만들 수 있었다. 차트 하나 만드는 데 걸리는 시간이 굉장히 많이 줄어들었다.
실시간 데이터 확인도 매우 용이했다. 데이터가 실시간으로 Elasticsearch에 인덱싱되고, Kibana를 통해 즉시 시각화할 수 있었다. 이 덕분에 데이터의 변화를 실시간으로 모니터링하고 분석할 수 있었다. 업무 효율성이 정말 많이 높아진 것 같다.
오늘은 ELK 스택의 편리함을 새삼 다시 느끼며, 앞으로 데이터 시각화 작업이 더욱 기대되었다. 이 도구를 통해 더 많은 데이터를 쉽게 분석하고, 유의미한 인사이트를 도출할 수 있을 것 같다.
'나의보물들 > ELK' 카테고리의 다른 글
| [ELK] Logstash구동 시 자바 버전 에러 (0) | 2024.07.23 |
|---|---|
| [ELK] Linux(Ubuntu)에서 ELK 스택 구축 (3) | 2024.07.21 |
| [ELK] kibana.bat 실행 후 CMD창 꺼지는 오류 해결 방법 (0) | 2024.07.18 |
'나의보물들/ELK' Related Articles
more

